一个好的拼音输入法能极大提升中文使用者的生活效率。从最早智能机上的 Bag of Words 词袋模型(按照语料库中汉字出现频率排序)到使用 n-gram 语言模型的 viterbi 方法,再到从 RNN 派生出的 seq2seq 深度学习方法、云输入工具等,都是利用可用算力对拼音转文字的尝试。
这次实验中以 n-gram 为主,使用三元模型构建拼音输入法,并与 seq2seq 进行对比,实现拼音到汉字序列的转换,在测试集上的准确度达到 0.79(句)与 0.95(字)。
整体内容分为四大块:语料库选择与清洗、模型的具体实现、参数选择与优化、结果分析。
语料库
语料库是拼音输入法的灵魂。从实际实验情况来看,从 n-gram 升级到 NNLM 以致 seq2seq 模型,投入大量 GPU 时间训练所带来的提升可能还没有清洗语料库带来的提升大。对语料库的处理主要分为两个部分,即爬取与清洗:
爬取
给出的语料库为 2016 全年的新浪新闻。
四年来中文语言的变化非常之大,新的句式频繁出现,专有名词也在不断产生,因此爬取了近三个月的新浪新闻数据与清华新闻网上的全部数据;新闻的句式较为正式,在日常拼音输入法的使用中还会涉及很多口语化表达,因此引入微博、贴吧、豆瓣与知乎的数据集。
清洗
拼音输入法只能输入汉字,因此针对标点切分
delims = r',|,|\.|。|、|\(|(|\)|)|<|《|>|》|\'|\"|“|”|【|】|:|…|·|\t|\#|\-'
仅提取纯汉字内容
def is_type(word):
if len(word) > 1:
return min('\u4e00' <= char <= '\u9fff' for char in word]
else:
return False
序列化
语料库大小为
| 语料库 | 大小 /MB | 清洗后 /MB | 条数 /w |
|---|---|---|---|
| 新浪新闻 /旧 | 948 | 611 | 1761 |
| 新浪新闻 /新 | 559 | 179 | 500 |
| 清华新闻 | 464 | 51 | 138 |
| 微博数据 | 536 | 110 | 428 |
| 贴吧数据 | 425 | 144 | 498 |
| 豆瓣数据 | 643 | 186 | 294 |
| 知乎问答 | 3712 | 1034 | 3203 |
使用 pypinyin 对汉字序列标音,并建立字典将拼音与汉字分别映射到连续整数序列
利用 pickle 将序列化后语料库存储到二进制文件,共四种组合如下
| 语料库 | 大小 /MB | 拼音数量 | 汉字数量 |
|---|---|---|---|
| 给定新闻 | 786 | 410 | 9006 |
| 全部新闻 社交平台 |
2252 | 416 | 11080 |
| 知乎问答 | 1935 | 414 | 12494 |
| 全部语料库 | 4198 | 416 | 13623 |
模型
n-gram
对于拼音序列 #$w_i^n#$,最有可能与之对应的汉字序列 #$t_i^n#$ 为
$$\hat{t}_i^n=\mathop{\arg\max}_{t_i^n}P(t_i^n|w_i^n)$$
使用贝叶斯公式
$$\hat{t}_i^n=\mathop{\arg\max}_{t_i^n}\frac{P(w_i^n|t_i^n)\cdot P(t_1^n)}{P(w_1^n)}$$
也即
$$\hat{t}_i^n=\mathop{\arg\max}_{t_i^n}P(w_i^n|t_i^n)\cdot P(t_1^n)$$
使用马尔可夫假设
$$P(w_1^n|t_1^n)\approx\prod_{i=1}^nP(w_i|t_i)$$
二元模型
$$P(t_1^n)\approx\prod_{i=1}^nP(t_i|t_{i-1})$$
三元模型
$$P(t_1^n)\approx\prod_{i=1}^nP(t_i|t_{i-2}t_{i-1})$$
其中二元模型有一个开始符 ^ 与一个终结符 $,三元模型分别有两个
进行平滑化处理
$$P(t_i|t_{i-1})=\lambda\cdot P(t_i|t_{i-1})+(1-\lambda)\cdot P(t_i)$$
并定义字与拼音的权重比为 #$k#$,即
$$P(t_i|t_{i-2}t_{i-1})\cdot P(t_i|w_i)^k$$
然后使用 viterbi 算法求出最大可能性选择
seq2seq
先构建 conv1d bank 提取尽可能多的输入序列特征,加入 highway 促进梯度流动
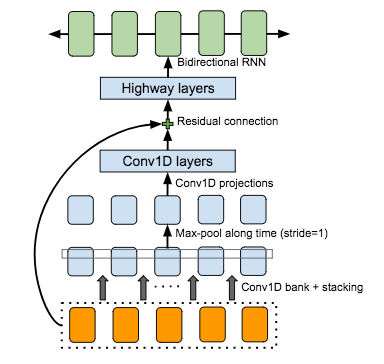
参考自 Kyubyong 并针对拼音序列进行改进,加入新的语料库训练模型
参数选择与结果分析
n-gram
分析
预设 #$\lambda=0.95#$, #$k=0.1#$ 训练的结果为(给定的测试集)
| 语料库 | 数据大小 /MB | 句准确率 | 字准确率 |
|---|---|---|---|
| 给定新闻 | 430 | 0.641 | 0.907 |
| 全部新闻 社交平台 |
611 | 0.728 | 0.939 |
| 知乎问答 | 563 | 0.732 | 0.937 |
| 全部语料库 | 895 | 0.784 | 0.951 |
使用给定新闻语料库对 #$\lambda#$ 进行分析,固定 #$k=0#$
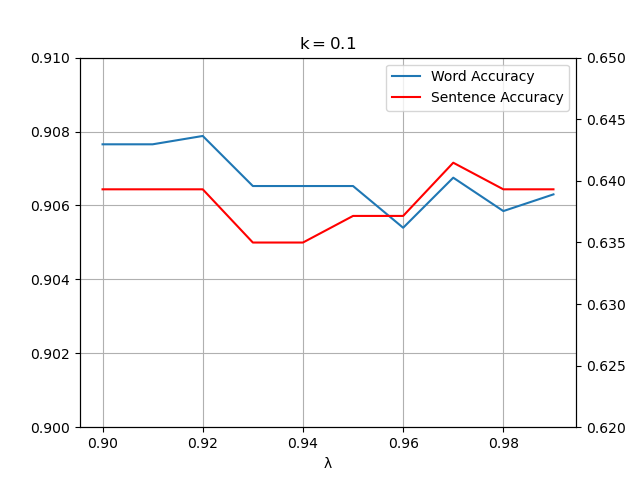
可以看到 #$\lambda#$ 在 #$[0.90, 1)#$ 上差异不大
使用全部语料库对 #$k#$ 进行分析,固定 #$\lambda=0.95#$
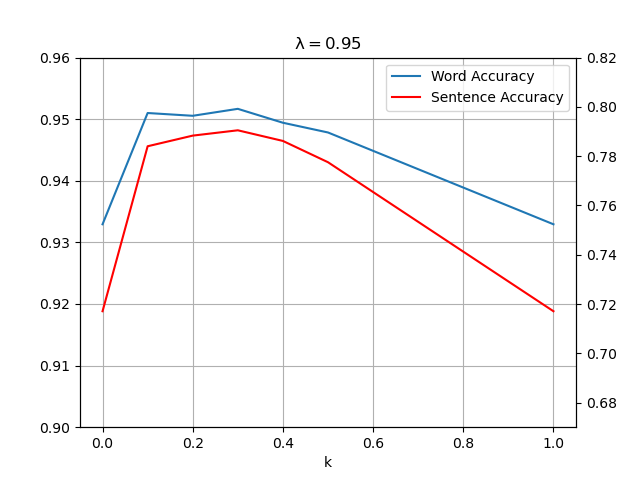
可以看到在 #$k=0.3#$ 时正确率达到峰值
结论
对于一般模型,普遍认为正确率在 #$\lambda#$ 取 #$[0.9, 1.0)#$,#$k#$ 取 #$[0.1, 0.3]#$ 时达到峰值
采用全部语料库作为训练集,在 #$\lambda=0.95#$, #$k=0.3#$ 时准确度达到峰值 0.790 与 0.952
实验得出最优参数为
| 语料库 | #$\lambda#$ | #$k#$ | 句准确率 | 字准确率 |
|---|---|---|---|---|
| 给定新闻 | 0.95 | 0.1 | 0.641 | 0.907 |
| 全部新闻 社交平台 |
0.95 | 0.3 | 0.739 | 0.941 |
| 知乎问答 | 0.95 | 0.1 | 0.732 | 0.937 |
| 全部语料库 | 0.95 | 0.3 | 0.790 | 0.952 |
一些典型错句
- (她)是我的母亲 - 因果关系
- 给阿姨(倒)一杯卡布奇诺 - 倒序相关
- 我去给你买一个(橘子) - 受限于 tri-gram 长度
- 你吼(辣么)大声干什么嘛 - 网络流行语
- (寻寻觅觅冷冷清清凄凄惨惨戚戚) - 古文
- (碳碳键键能能否否定定律) - 人类也无法轻易识别的句子
一些典型正确句子
- 正确率接近 80%,展示具体样例没有什么意义
seq2seq
使用了给定数据的 10% 规模进行训练,在给定的数据集上句、字准确度分别为 0.33 和 0.80
字准确度与 n-gram 相近,如果改为 top-k 匹配测试句准确度可能会大幅上升
使用 20% 规模进行训练,在给定数据集上句、字准确度分别为 0.41 和 0.87
使用更大规模语料库进行训练并等待完全收敛,会有可以预见的高准确率
To-dos
- 收集诗词与古文语料库,增加对古诗文的定向匹配
- 进行 viterbi 算法时仅选取 top-k 概率以加快速度
- 优化序列化语料库构建方式,使之支持增量添加
- 继续进行 seq2seq 实验