之前和一个经管的同学聊天,她提到想做历史上人物的足迹图,比如亚里士多德曾经到访过哪些城市。我高中古文学得一塌糊涂,对历史人物也没太大兴趣,但直观地用地图来展示趋势听起来很有意思;正好之前 Pero 训练扫黄 bot 的时候帮他爬过清华新闻网上的所有新闻数据,不如就用这份语料库试试看吧!于是就有了这篇文章。
工具选择
先查到了 pyecharts,可以绘制很多种类的图表,不过后来觉得图片不好看就没有继续用下去。值得注意的是,在 echarts-china-provinces-pypkg 和 echarts-china-cities-pypkg 包中提供了一份比较完整的中国省市地区经纬度表,省去了爬地理信息的过程。摘录如下:
// city_coordinates.json
{"阿城": [126.58, 45.32], "阿克苏": [80.19, 41.09], "阿勒泰": [88.12, 47.5], ...}
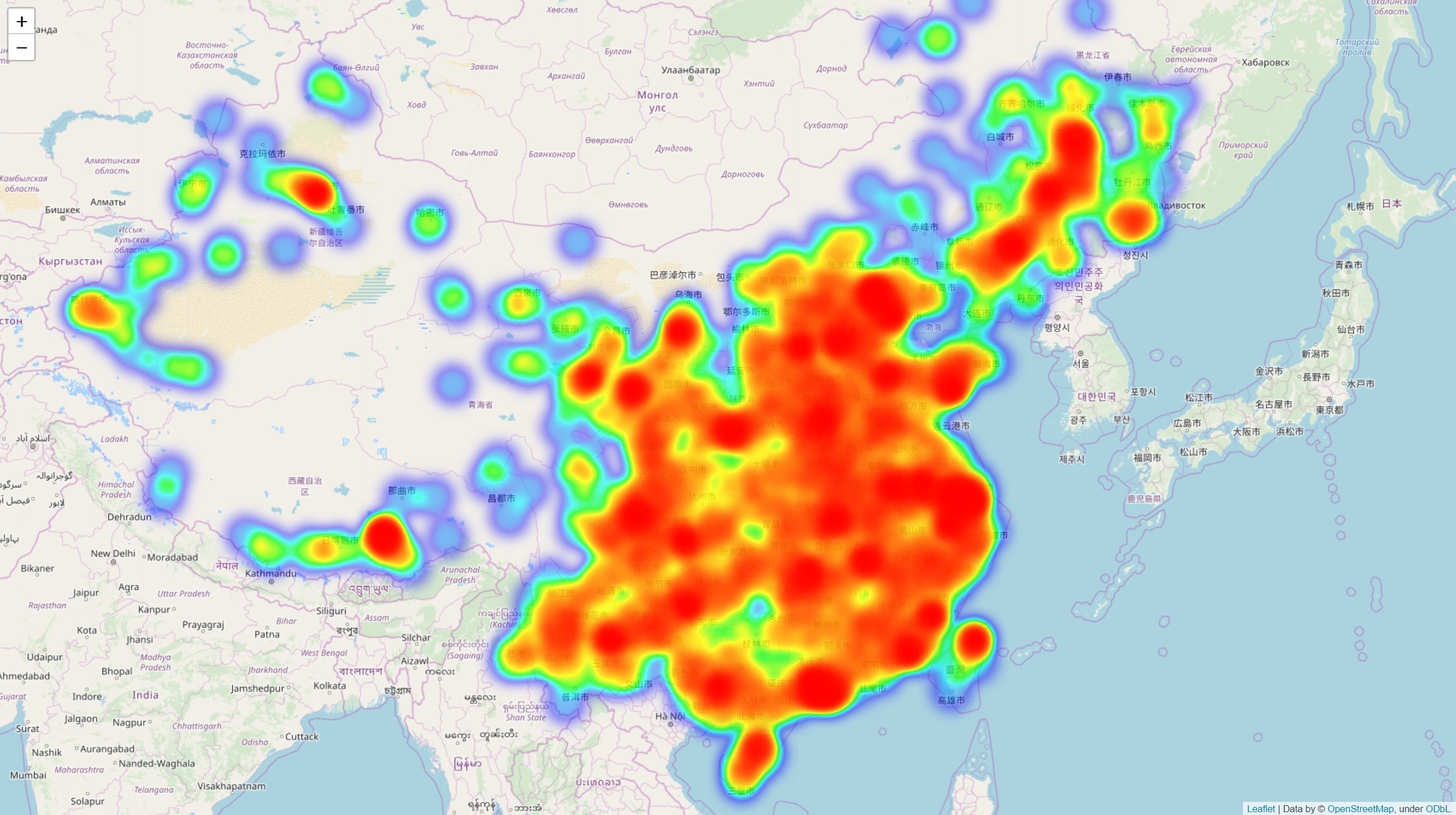
之后使用 folium 进行热力图的绘制。
切词
首先需要对清华新闻网的文本信息进行切词从而进行地理位置的匹配,之前一直在用 pkuseg,准确率比自家的 thulac 高,但是在长文本上实在太慢了 :( 最后选择了 jieba 分词,cut_for_search 功能能比较好地提取出地理位置词语。数据集可以从之前爬过的 清华新闻 获取,也可以自己选择其他数据来源比如小说等。
data = json.load(open('news.json', 'r', encoding='utf-8'))
data = sum(data.values(), [])
words = list() # word lists
jieba.enable_paddle()
for news in tqdm(data):
try:
words += jieba.cut_for_search(news['content'])
except:
pass
json.dump(words, open('words.json', 'w', encoding='utf-8'))
标记
使用 python3 高效的 Counter 类完成词语的频次统计(这个包底层是用 C 实现的,非常快)
words = json.load(open('news.json', encoding='utf-8'))
words = Counter(words)
之后按照 folium 的数据格式标记数据,格式为 [lats, lons, weights],地图起始坐标选择为 [35, 110],缩放 5x。需要注意到 pyecharts 提供的经纬信息正好与 folium 相反,需要手动调整。新闻数据量很大,分词后词表更大,引入 tqdm 显示进度条会直观一些;如果数据集更大的话还可以考虑使用 multiprocessing 多线程加速(这个也是 Pero 教的,无损替换 map,太好用了)
geo = json.load(open('city_coordinates.json', encoding='utf-8'))
data = list()
for k, v in tqdm(geo.items()):
if c := words[k]:
data.append([v[1], v[0], c])
map_osm = folium.Map(location=[35, 110], zoom_start=5)
HeatMap(data).add_to(map_osm)
map_osm.save('news.html')
这样得到的 html 文件就是绘制热力图之后的世界地图了!
成品 news.html 下载